[모두의 딥러닝] 경사하강법(Gradient Descent)
위 글은 [모두의 딥러닝 (개정 2판)] 을 바탕으로 학습하여 작성한 글입니다.
경사 하강법의 개요
앞서 포스트에서 평균 제곱 오차로 선형 일차 함수의 오차가 가장 작은 기울기를 구하는 과정을 거쳤습니다.
구한 기울기 a와 오차 사이에는 다음과 같은 이차 함수의 그래프로 나타남을 알 수 있습니다.
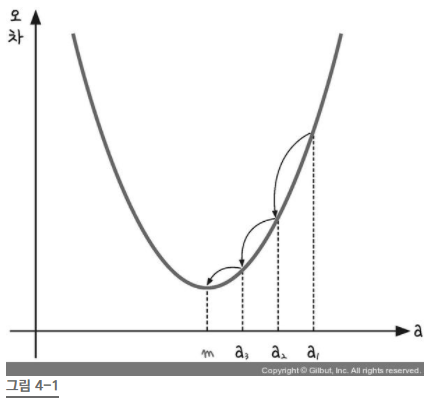
해당 그래프에서는 오차가 가장 작은 점은 기울기 a가 m일 경우입니다.
즉, 해당 그래프의 미분 값이 0인 점이 되는 것입니다.
경사 하강법은 이렇게 반복적으로 기울기 a를 변화시켜서 m의 값을 찾아내는 방법을 말합니다.
학습률
만약 앞선 경사하강법을 적용하는 과정에서 기울기의 부호를 바꿔 이동시킬 때 적절한 거리를 찾지 못해 너무 멀리 이동시키면 a 값이 한점으로 모이지 않고 엉뚱한 곳으로 솟아버릴 수 있습니다.
이때 이동거리를 정해주는 것이 학습률입니다.
딥러닝에서 학습률의 값을 적절히 바꾸면서 최적의 학습률을 찾는 것은 중요한 최적화 과정 중 하나입니다.
정리하면, 경사 하강법은 오차의 변화에 따라 이차 함수 그래프를 만들고 적절한 학습률을 설정해 미분 값이 0인 지점을 구하는 것입니다.
파이썬을 이용한 경사 하강법 코드
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#공부시간 X와 성적 Y의 리스트를 만듭니다.
data = [[2, 81], [4, 93], [6, 91], [8, 97]]
x = [i[0] for i in data]
y = [i[1] for i in data]
#그래프로 나타내 봅니다.
plt.figure(figsize=(8,5))
plt.scatter(x, y)
plt.show()
#리스트로 되어 있는 x와 y값을 넘파이 배열로 바꾸어 줍니다.(인덱스를 주어 하나씩 불러와 계산이 가능해 지도록 하기 위함입니다.)
x_data = np.array(x)
y_data = np.array(y)
# 기울기 a와 절편 b의 값을 초기화 합니다.
a = 0
b = 0
#학습률을 정합니다.
lr = 0.03
#몇 번 반복될지를 설정합니다.
epochs = 2001
#경사 하강법을 시작합니다.
for i in range(epochs): # epoch 수 만큼 반복
y_hat = a * x_data + b #y를 구하는 식을 세웁니다
error = y_data - y_hat #오차를 구하는 식입니다.
a_diff = -(2/len(x_data)) * sum(x_data * (error)) # 오차함수를 a로 미분한 값입니다.
b_diff = -(2/len(x_data)) * sum(error) # 오차함수를 b로 미분한 값입니다.
a = a - lr * a_diff # 학습률을 곱해 기존의 a값을 업데이트합니다.
b = b - lr * b_diff # 학습률을 곱해 기존의 b값을 업데이트합니다.
if i % 100 == 0: # 100번 반복될 때마다 현재의 a값, b값을 출력합니다.
print("epoch=%.f, 기울기=%.04f, 절편=%.04f" % (i, a, b))
# 앞서 구한 기울기와 절편을 이용해 그래프를 그려 봅니다.
y_pred = a * x_data + b
plt.scatter(x, y)
plt.plot([min(x_data), max(x_data)], [min(y_pred), max(y_pred)])
plt.show()코딩하는 과정에서 우리가 궁극적으로 구하고자 하는 것은 a와 b임을 기억해야합니다.
따라서 필요한 값인 a와 b를 중심으로 미분을 해야하기 때문에 편미분을 해야합니다.
$$a로 편미분 한 결과={2\over{n}}{\sum(ax_{i}+b-y_{i})x_{i}}$$
$$b로 편미분 한 결과={2\over{n}}{\sum(ax_{i}+b-y_{i})}$$
구한 미분 값은 항상 가파른 방향으로 향하기 때문에 구한 값에 (-)를 취해주어야 합니다.
또한 a와 b를 업데이트 할 경우 Gradient를 조절해주기 위해 Learing rate가 필요합니다.
다중 선형 회귀
하나의 변수가 아닌 여러 개일 경우 다중 선형 회귀의 사용이 필요합니다.
다중 선형 회귀를 사용하면 추가 정보를 통해 더 정확한 예측이 가능합니다.
$$y=a_{1}x_{1} + a_{2}x_{2} + b$$
파이썬을 이용한 다중 선형 회귀 코드
x의 값이 두 개이므로 다음과 같이 data 리스트를 만들고 x1과 x2라는 두 개의 독립 변수 리스트를 만듭니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits import mplot3d # 3D 그래프를 그리는 라이브러리 가져오기
#공부시간 X와 성적 Y의 리스트를 만듭니다.
data = [[2, 0, 81], [4, 4, 93], [6, 2, 91], [8, 3, 97]]
x1 = [i[0] for i in data]
x2 = [i[1] for i in data]
y = [i[2] for i in data]data 그래프를 그리기 위해 3D 그래프를 그려주는 라이브러리를 사용합니다.
#그래프로 확인해 봅니다.
ax = plt.axes(projection='3d')
ax.set_xlabel('study_hours')
ax.set_ylabel('private_class')
ax.set_zlabel('Score')
ax.dist = 11
ax.scatter(x1, x2, y)
plt.show()a1과 a2 그리고 b 각각의 값에 대해 편미분을 합니다.
#리스트로 되어 있는 x와 y값을 넘파이 배열로 바꾸어 줍니다.(인덱스를 주어 하나씩 불러와 계산이 가능해 지도록 하기 위함입니다.)
x1_data = np.array(x1)
x2_data = np.array(x2)
y_data = np.array(y)
# 기울기 a와 절편 b의 값을 초기화 합니다.
a1 = 0
a2 = 0
b = 0
#학습률을 정합니다.
lr = 0.02
#몇 번 반복될지를 설정합니다.(0부터 세므로 원하는 반복 횟수에 +1을 해 주어야 합니다.)
epochs = 2001
#경사 하강법을 시작합니다.
for i in range(epochs): # epoch 수 만큼 반복
y_pred = a1 * x1_data + a2 * x2_data + b #y를 구하는 식을 세웁니다
error = y_data - y_pred #오차를 구하는 식입니다.
a1_diff = -(2/len(x1_data)) * sum(x1_data * (error)) # 오차함수를 a1로 미분한 값입니다.
a2_diff = -(2/len(x2_data)) * sum(x2_data * (error)) # 오차함수를 a2로 미분한 값입니다.
b_new = -(2/len(x1_data)) * sum(y_data - y_pred) # 오차함수를 b로 미분한 값입니다.
a1 = a1 - lr * a1_diff # 학습률을 곱해 기존의 a1값을 업데이트합니다.
a2 = a2 - lr * a2_diff # 학습률을 곱해 기존의 a2값을 업데이트합니다.
b = b - lr * b_new # 학습률을 곱해 기존의 b값을 업데이트합니다.
if i % 100 == 0: # 100번 반복될 때마다 현재의 a1, a2, b값을 출력합니다.
print("epoch=%.f, 기울기1=%.04f, 기울기2=%.04f, 절편=%.04f" % (i, a1, a2, b))여기서 epoch는 입력 값에 대해 몇 번이나 반복하여 실험했는지를 나타냅니다. 우리가 설정한 실험을 반복하고 100번 마다 결과를 내는 코드입니다.
결과는 다음과 같이 3차원 예측 평면으로 나타납니다.
